扣库存的场景及问题
扣库存是电商系统里一个非常基础的操作。
在业务上,它必须要能达到:
- 不超卖
- 重试时,不出现假卖
在非功能需求上,它需要做到:
- 应对高并发的流量
单件商品扣库存方案及其优化
约定扣的库存数量为x
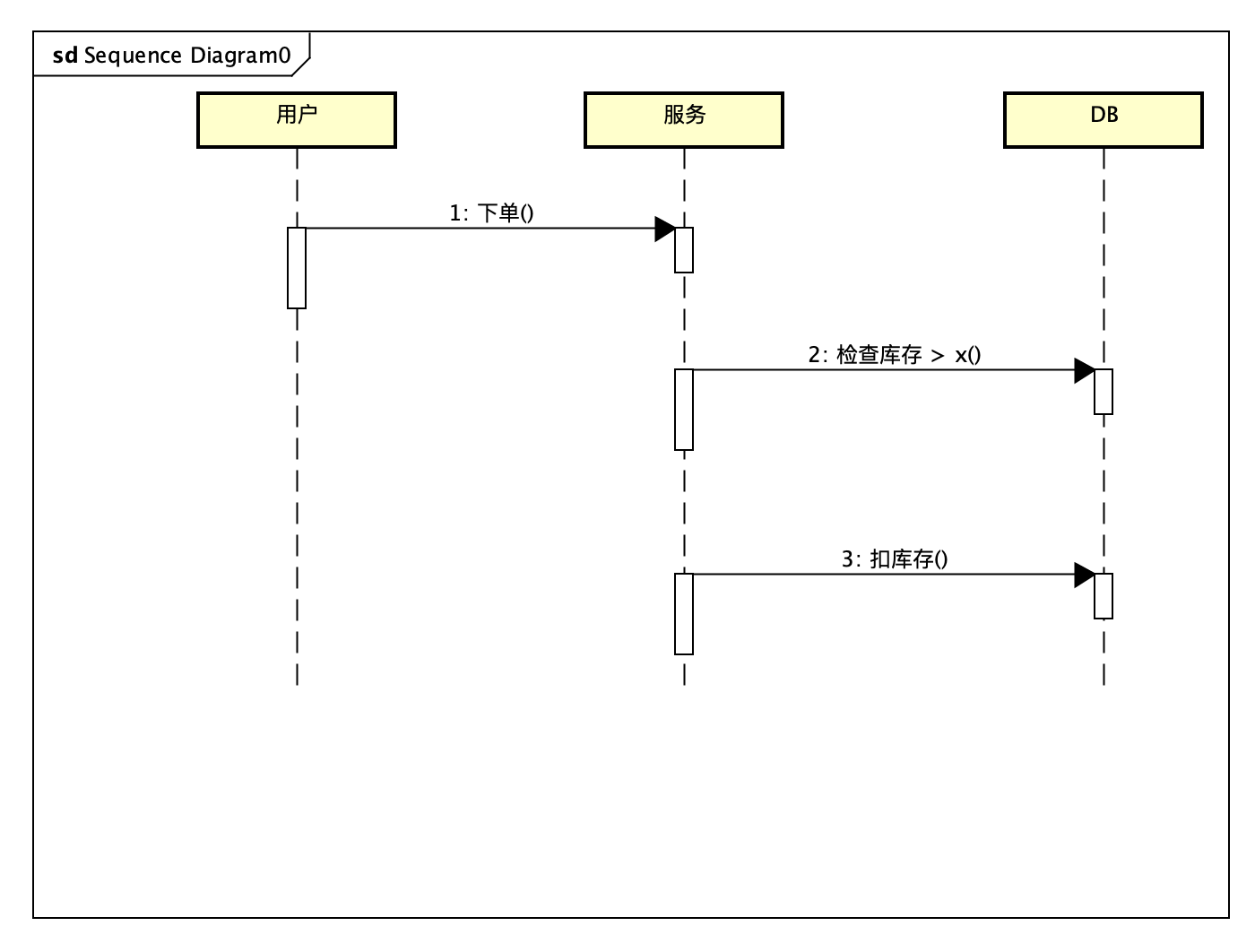
方案一 直接更新库存
|
|
由于库存检查是在服务里做的,并发现情况下,容易出现超卖。
设原来的库存是5,用户a扣了库存4,b扣了库存2,流程如下:
- 用户a检查库存
- 用户b检查库存
- 用户a扣库存4
- 用户b扣库存2
- 最终库存为-1
方案一优化 加锁(事务)
为了解决并发修改的问题,可以通过增加锁(事务),把并发变成串行。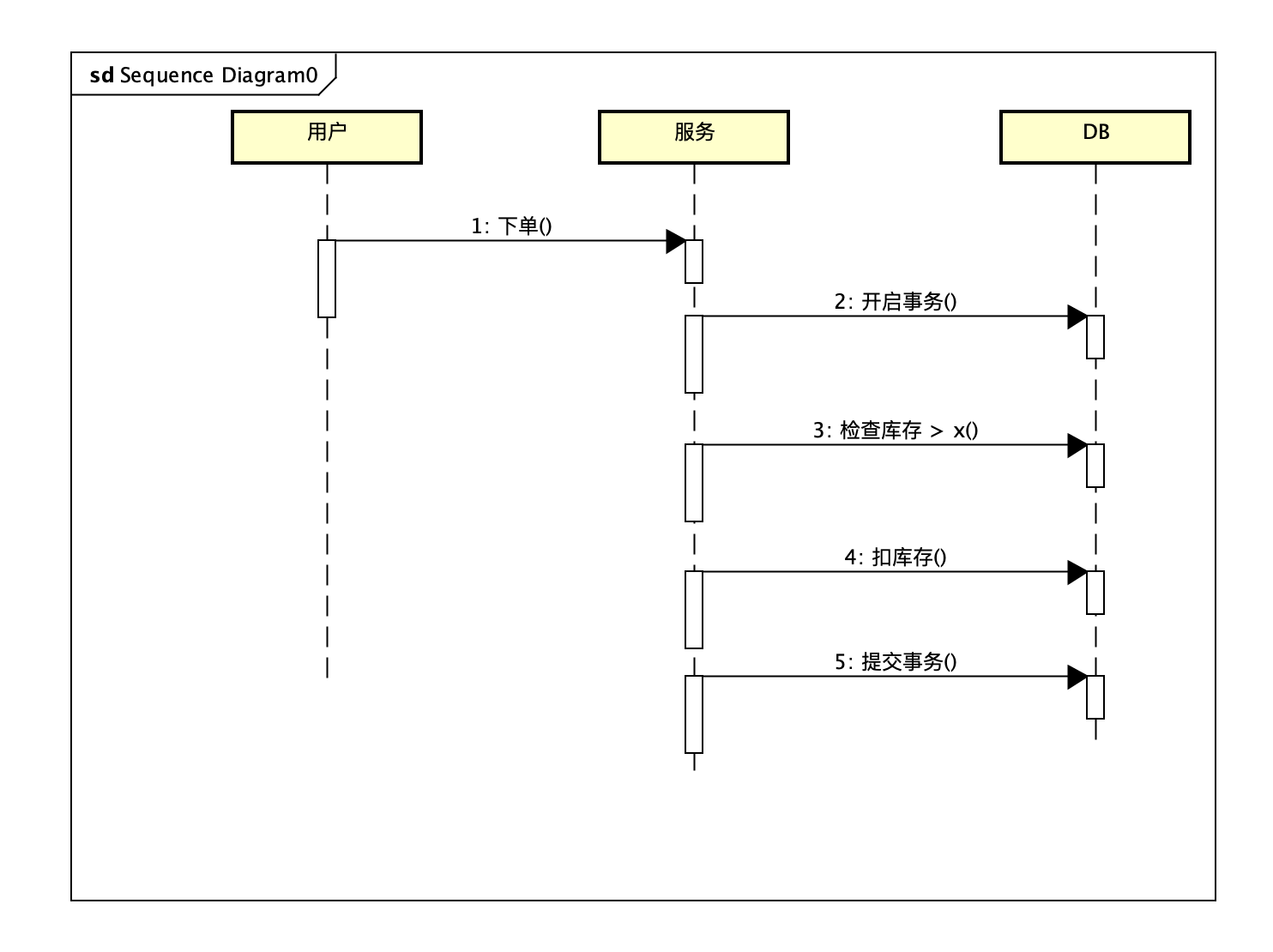
这种方案可以解决并发上的问题,但是由于开启事务(锁)的时间较长,会导致严重的性能问题,同时,对于分库后的多个商品,还会存在多库事务的分布式事务问题,成本很高。
方案三 优化锁:减少锁的持有时间
为了优化锁,一个方式是减少锁的持有时间。可以考虑在扣库存时,增加一把乐观锁
|
|
方案四 高并发下的扣库存设计
方案三能解决大部分场景下的扣库存问题,但当碰到秒杀、大促等场景时,由于商品库存有限,扣库存失败的概率很高,这里如果重复尝试扣库存,会对系统造成较大的压力,减少吞吐。
因此需要对并发的流量进行限流。可以考虑对每个商品的并发数加队列或锁,以减少同时并发的数目失败的概率。对于特别热门的商品,还可以把一个商品拆成多个子商品,以增大并发数目。
扣库存的重试
当由于某种原因扣库存失败时,可能需要进行重试。由于扣库存不是一个幂等的操作,容易造成空卖。
可以通过给每个扣库存操作增加一个token来解决这个问题。当token已经使用过时,再次请求直接忽略。
多件商品扣库存方案及其优化
相比于单件商品的扣库存,同时扣多件商品的库存,需要考虑:
- 同时有多个商品,修改、回滚的数目比较多
- 操作商品的模式
最简单的方案是直接把多个商品放在一个事务来实现,但是这样有几个问题:
- 事务时间比较长,还容易造成死锁
- 商品越多,扣库存失败的可能性越大
对于第一个问题,可以把一个事务拆成多个事务,以加大系统吞吐量。这样做还有一个好处,就是这些商品可以不用在同一个库里了(mysql的事务是基于库实例实现的),从而避开了分布式事务的成本。
对于第二个问题,可以使用二阶段提交,先锁定所有商品的库存,然后统一提交。避免频繁回滚。
从扣库存看高并发
扣库存是一个典型的业务型系统,具有以下特点:
- 并发量高
- 数据量大
- 逻辑较轻
它的难点主要体现在:
- 大量高速交易
- 数据的一致性
- 应对各种业务、系统异常情况